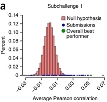
 Los datos de toxicidad en líneas celulares de 156 compuestos ambientales permitieron relacionar las propiedades estructurales de los productos con los resultados experimentales y perfiles genómicos. Puede consultar el reporte en Eduati F, Mangravite LM, Wang T, Tang H, Bare JC, Huang R, et al. Prediction of human population responses to toxic compounds by a collaborative competition. Nature Biotechnology 2015; doi:10.1038/nbt.3299.
Los datos de toxicidad en líneas celulares de 156 compuestos ambientales permitieron relacionar las propiedades estructurales de los productos con los resultados experimentales y perfiles genómicos. Puede consultar el reporte en Eduati F, Mangravite LM, Wang T, Tang H, Bare JC, Huang R, et al. Prediction of human population responses to toxic compounds by a collaborative competition. Nature Biotechnology 2015; doi:10.1038/nbt.3299.
Filed under Algoritmos, Bases de datos, Diagnóstico by on . Comment. ![]()